Obtenga beneficios adicionales
Aún no tiene una suscripción a Virtual Pro?
Para acceder a este contenido se requiere una suscripción
Obtenga beneficios adicionales
Aún no tiene una suscripción a Virtual Pro?
Para acceder a este contenido se requiere una suscripción
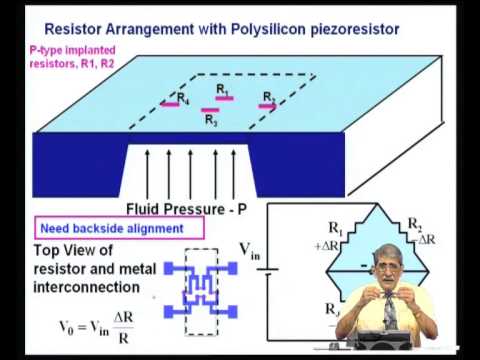
Para el análisis de datos en muestras complejas, el usuario recurre comúnmente a los procedimientos tradicionales que están implementados en los paquetes estadísticos computacionales convencionales en donde, por defecto, suponen que las observaciones obtenidas en la muestra son independientes e idénticamente distribuidas. Esto los lleva a ignorar el diseño de muestreo complejo, o bien la forma estructural que presenta la población de interés, ocasionando graves distorsiones en las inferencias de tipo analítico. Con base en lo anterior, aquí se examinan algunas alternativas para estimar la matriz de covarianza. Además, se proponen algunas correcciones simples para obtener estimadores consistentes de los errores estándar del vector de coeficientes en un modelo de regresión lineal.
Esta es una versión de prueba de citación de documentos de la Biblioteca Virtual Pro. Puede contener errores. Lo invitamos a consultar los manuales de citación de las respectivas fuentes.
Trabajo de curso:
Reconciliación de datos
Trabajo de curso:
Aplicación de la ingeniería de métodos en el proceso de producción de paletas en la empresa cubana Servicios Logísticos S.A. Representación Centro
Artículo:
Influencia del espesor de las piezas en la estructura metalográfica de las uniones soldadas
Artículo:
Evaluación de la eficacia del uso de materias primas y materiales en el departamento de altos hornos de una acería
Artículo:
Estudio de los servicios de aplicaciones en redes IP para la gestión del mantenimiento industrial
Libro:
Metodología del marco lógico para la planificación, el seguimiento y la evaluación de proyectos y programas
Presentación:
Estudio de movimientos y tiempos
Artículo:
Estudio sobre la evaluación de la sostenibilidad de los productos innovadores
Tesis:
Materiales y prácticas de construcción sostenible
Virtual Pro es un portal virtual de formación, investigación y comunicación especializado en procesos industriales.

� 2021, Virtual Pro �, una marca de Grupo INGCO. Todos los derechos reservados