Obtenga beneficios adicionales
Aún no tiene una suscripción a Virtual Pro?
Para acceder a este contenido se requiere una suscripción
Obtenga beneficios adicionales
Aún no tiene una suscripción a Virtual Pro?
Para acceder a este contenido se requiere una suscripción
Existen muchas alternativas para realizar minería de datos masivos, entre ellas algoritmos neuronales, máquinas de vectores de soporte, algoritmos de asociación, algoritmos genéticos y algoritmos de conglomeración (clustering). En este artículo se realiza una descripción general acerca de distintos algoritmos de conglomeración ―de partición, jerárquicos, de densidad, basados en grillas y basados en modelos― que resaltan las características 4V de los datos masivos: volumen, variedad, velocidad y valor.
Esta es una versión de prueba de citación de documentos de la Biblioteca Virtual Pro. Puede contener errores. Lo invitamos a consultar los manuales de citación de las respectivas fuentes.
Artículo:
Un modelo multifractal simplificado para flujos de tráfico en redes de computadoras de alta velocidad
Software:
[Software WISKI TV]
Artículo:
Nuevo algoritmo heurístico para tráfico dinámico en redes ópticas WDM
Artículo:
Análisis del papel de los agentes de ciencia, tecnología e innovación del sistema regional de innovación del área metropolitana del Valle de Aburrá (Colombia)
Video:
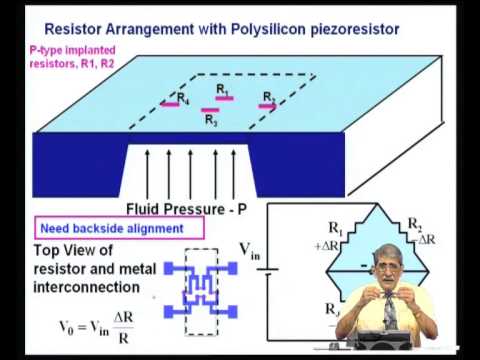
Introducción a big data, machine learning y data mining
Artículo:
Creación de empresas y estrategia : reflexiones desde el enfoque de recursos
Artículo:
Importancia, manejo y control de extraíbles e incrustaciones (pitch) en la fabricación de papel
Artículo:
Estudio sobre la evaluación de la sostenibilidad de los productos innovadores
Libro:
Planta de tratamiento de aguas residuales
Virtual Pro es un portal virtual de formación, investigación y comunicación especializado en procesos industriales.

� 2021, Virtual Pro �, una marca de Grupo INGCO. Todos los derechos reservados